2026
Co-Generative De Novo Functional Protein Design
Xinrui Chen, Yizhen Luo, Siqi Fan, Zaiqing Nie
International Conference on Machine Learning (ICML) 2026
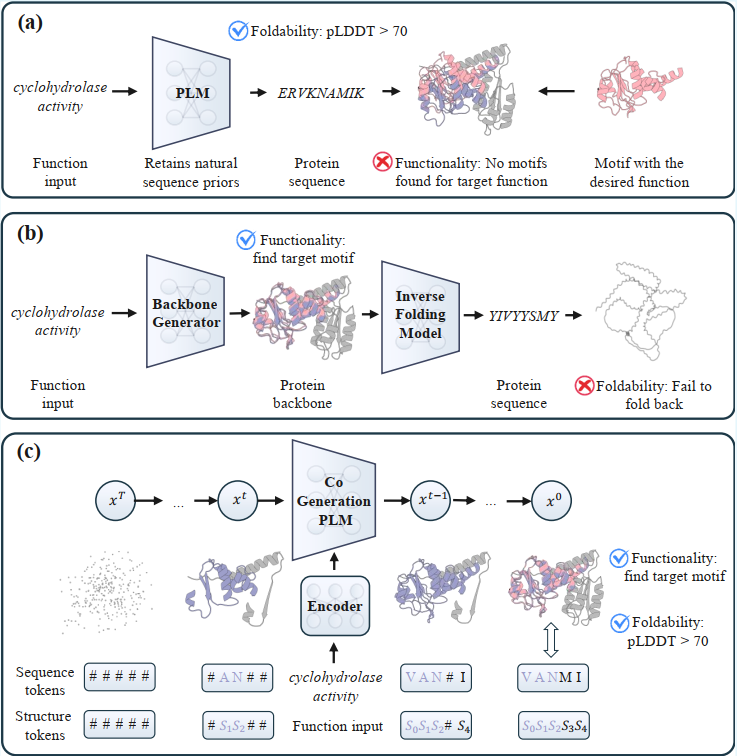
De novo functional protein design aims to generate protein sequences that realize specified biochemical functions without relying on evolutionary templates, enabling broad applications in biotechnology and medicine. Existing approaches adopt either direct function-to-sequence mapping or decoupled structure-sequence generation strategies but often fail to achieve functionality and foldability simultaneously. To address this, we propose CodeFP, a Co-generative protein language model for de novo Functional Protein design that simultaneously decodes sequence and structure tokens, thereby enabling superior simultaneous realization of functionality and foldability. CodeFP utilizes functional local structures to enrich functional semantic encodings, overcoming the suboptimal translation of flat encodings into structure tokens, while introducing auxiliary functional supervision to alleviate training ambiguity stemming from the one-to-many structure-to-token mapping. Extensive experiments show that CodeFP consistently achieves average improvements of 6.1% in functional consistency and 3.2% in foldability over the strongest baseline.
Co-Generative De Novo Functional Protein Design
Xinrui Chen, Yizhen Luo, Siqi Fan, Zaiqing Nie
International Conference on Machine Learning (ICML) 2026
De novo functional protein design aims to generate protein sequences that realize specified biochemical functions without relying on evolutionary templates, enabling broad applications in biotechnology and medicine. Existing approaches adopt either direct function-to-sequence mapping or decoupled structure-sequence generation strategies but often fail to achieve functionality and foldability simultaneously. To address this, we propose CodeFP, a Co-generative protein language model for de novo Functional Protein design that simultaneously decodes sequence and structure tokens, thereby enabling superior simultaneous realization of functionality and foldability. CodeFP utilizes functional local structures to enrich functional semantic encodings, overcoming the suboptimal translation of flat encodings into structure tokens, while introducing auxiliary functional supervision to alleviate training ambiguity stemming from the one-to-many structure-to-token mapping. Extensive experiments show that CodeFP consistently achieves average improvements of 6.1% in functional consistency and 3.2% in foldability over the strongest baseline.
Reinforced Reasoning for End-to-End Retrosynthetic Planning
Chenyang Zuo, Siqi Fan, Yizhen Luo, Zaiqing Nie
TechReport 2026
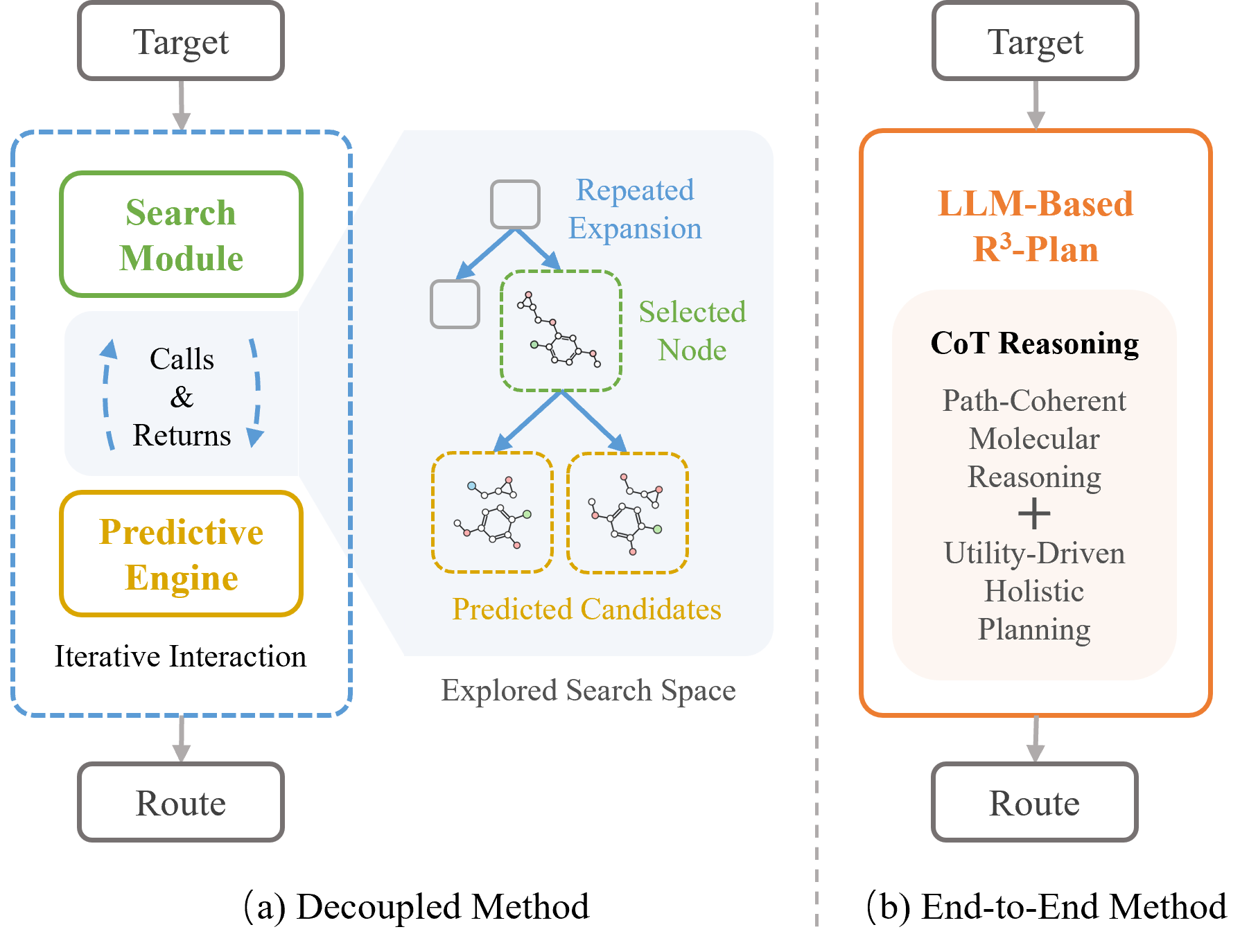
Retrosynthetic planning is a fundamental task in organic chemistry, yet remains challenging due to its combinatorial complexity. To address this, conventional approaches typically rely on hybrid frameworks that combine single-step predictions with external search heuristics, inevitably fracturing the logical coherence between local molecular transformations and global planning objectives. To bridge this gap and embed sophisticated strategic foresight directly into the model's chemical reasoning, we introduce ReTriP, an end-to-end generative framework that reformulates retrosynthesis as a direct Chain-of-Thought reasoning task. We establish a path-coherent molecular representation and employ a progressive training curriculum that transitions from reasoning distillation to reinforcement learning with verifiable rewards, effectively aligning stepwise generation with practical route utility. Empirical evaluation on RetroBench demonstrates that ReTriP achieves state-of-the-art performance, exhibiting superior robustness in long-horizon planning compared to hybrid baselines.
Reinforced Reasoning for End-to-End Retrosynthetic Planning
Chenyang Zuo, Siqi Fan, Yizhen Luo, Zaiqing Nie
TechReport 2026
Retrosynthetic planning is a fundamental task in organic chemistry, yet remains challenging due to its combinatorial complexity. To address this, conventional approaches typically rely on hybrid frameworks that combine single-step predictions with external search heuristics, inevitably fracturing the logical coherence between local molecular transformations and global planning objectives. To bridge this gap and embed sophisticated strategic foresight directly into the model's chemical reasoning, we introduce ReTriP, an end-to-end generative framework that reformulates retrosynthesis as a direct Chain-of-Thought reasoning task. We establish a path-coherent molecular representation and employ a progressive training curriculum that transitions from reasoning distillation to reinforcement learning with verifiable rewards, effectively aligning stepwise generation with practical route utility. Empirical evaluation on RetroBench demonstrates that ReTriP achieves state-of-the-art performance, exhibiting superior robustness in long-horizon planning compared to hybrid baselines.
2025
BioMedGPT-Mol: Multi-task Learning for Molecular Understanding and Generation
Chenyang Zuo*, Siqi Fan*, Zaiqing Nie (* equal contribution)
TechReport 2025
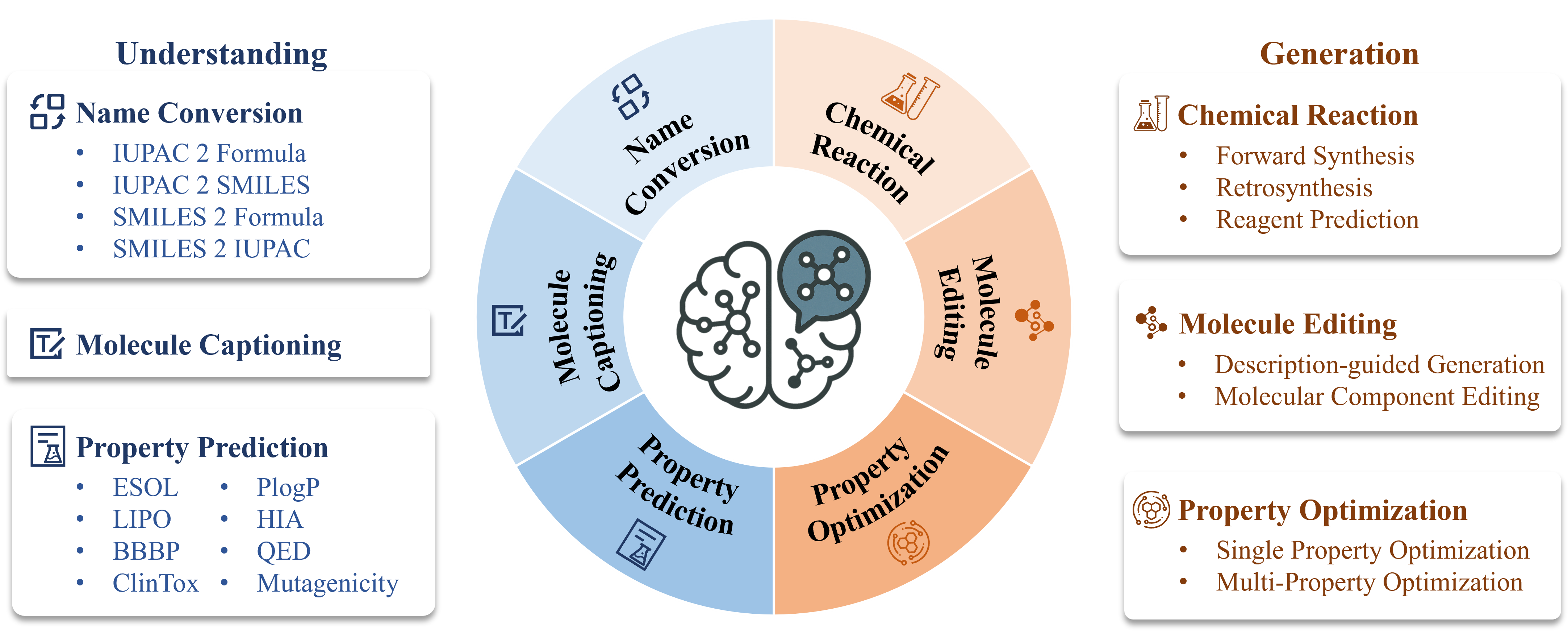
Molecules play a crucial role in biomedical research and discovery, particularly in the field of small molecule drug development. Given the rapid advancements in large language models, especially the recent emergence of reasoning models, it is natural to explore how a general-purpose language model can be efficiently adapted for molecular science applications. In this work, we introduce BioMedGPT-Mol, a molecular language model designed to support molecular understanding and generation tasks. By curating and unifying existing public instruction datasets, we have assembled a large-scale, comprehensive, and high-quality training dataset. The model is then fine-tuned through a meticulously designed multi-task learning framework. On a consolidated benchmark derived from LlaSMol, TOMG-Bench, and MuMOInstruct, BioMedGPT-Mol achieves remarkable performance. Our experimental results demonstrate that a general-purpose reasoning model can be effectively and efficiently post-trained into a professional molecular language model through a well-structured multi-task curriculum. We anticipate that our approach can be extended to other biomedical scientific domains.
BioMedGPT-Mol: Multi-task Learning for Molecular Understanding and Generation
Chenyang Zuo*, Siqi Fan*, Zaiqing Nie (* equal contribution)
TechReport 2025
Molecules play a crucial role in biomedical research and discovery, particularly in the field of small molecule drug development. Given the rapid advancements in large language models, especially the recent emergence of reasoning models, it is natural to explore how a general-purpose language model can be efficiently adapted for molecular science applications. In this work, we introduce BioMedGPT-Mol, a molecular language model designed to support molecular understanding and generation tasks. By curating and unifying existing public instruction datasets, we have assembled a large-scale, comprehensive, and high-quality training dataset. The model is then fine-tuned through a meticulously designed multi-task learning framework. On a consolidated benchmark derived from LlaSMol, TOMG-Bench, and MuMOInstruct, BioMedGPT-Mol achieves remarkable performance. Our experimental results demonstrate that a general-purpose reasoning model can be effectively and efficiently post-trained into a professional molecular language model through a well-structured multi-task curriculum. We anticipate that our approach can be extended to other biomedical scientific domains.
Biomedical Multimodal Reasoning for Molecular Understanding and Editing
Siqi Fan, Zaiqing Nie
TechReport 2025
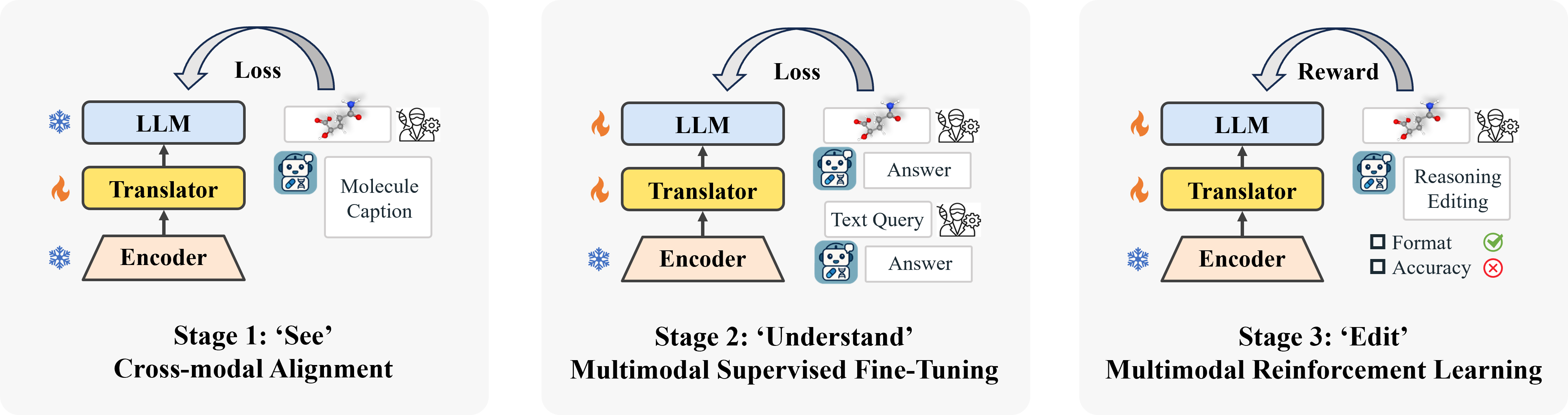
Molecule-centric scientific discovery relies on accurate molecular understanding and effective targeted editing. Although recent advances in large reasoning models have demonstrated significant performance advantages in natural language and vision-language tasks, existing approaches have yet to explore biomedical multimodal reasoning. In this paper, we introduce BioMedGPT-R1, a biomedical multimodal reasoning model, and investigate its capabilities in molecular understanding and editing. The model is trained using a three-stage `see-understand-edit' learning strategy. This approach guides the model to first `see' the molecule, then `understand' it, and finally `edit' it. The strategy comprises three key components: cross-modal alignment, multimodal supervised fine-tuning for efficient molecular understanding, and multimodal reinforcement learning for explainable molecular editing. To facilitate model evolution, we design specific instruction templates, a answer template, and a reward system. Experimental results demonstrate its effectiveness and highlight the power of multimodal reasoning in advancing molecular scientific discovery.
Biomedical Multimodal Reasoning for Molecular Understanding and Editing
Siqi Fan, Zaiqing Nie
TechReport 2025
Molecule-centric scientific discovery relies on accurate molecular understanding and effective targeted editing. Although recent advances in large reasoning models have demonstrated significant performance advantages in natural language and vision-language tasks, existing approaches have yet to explore biomedical multimodal reasoning. In this paper, we introduce BioMedGPT-R1, a biomedical multimodal reasoning model, and investigate its capabilities in molecular understanding and editing. The model is trained using a three-stage `see-understand-edit' learning strategy. This approach guides the model to first `see' the molecule, then `understand' it, and finally `edit' it. The strategy comprises three key components: cross-modal alignment, multimodal supervised fine-tuning for efficient molecular understanding, and multimodal reinforcement learning for explainable molecular editing. To facilitate model evolution, we design specific instruction templates, a answer template, and a reward system. Experimental results demonstrate its effectiveness and highlight the power of multimodal reasoning in advancing molecular scientific discovery.
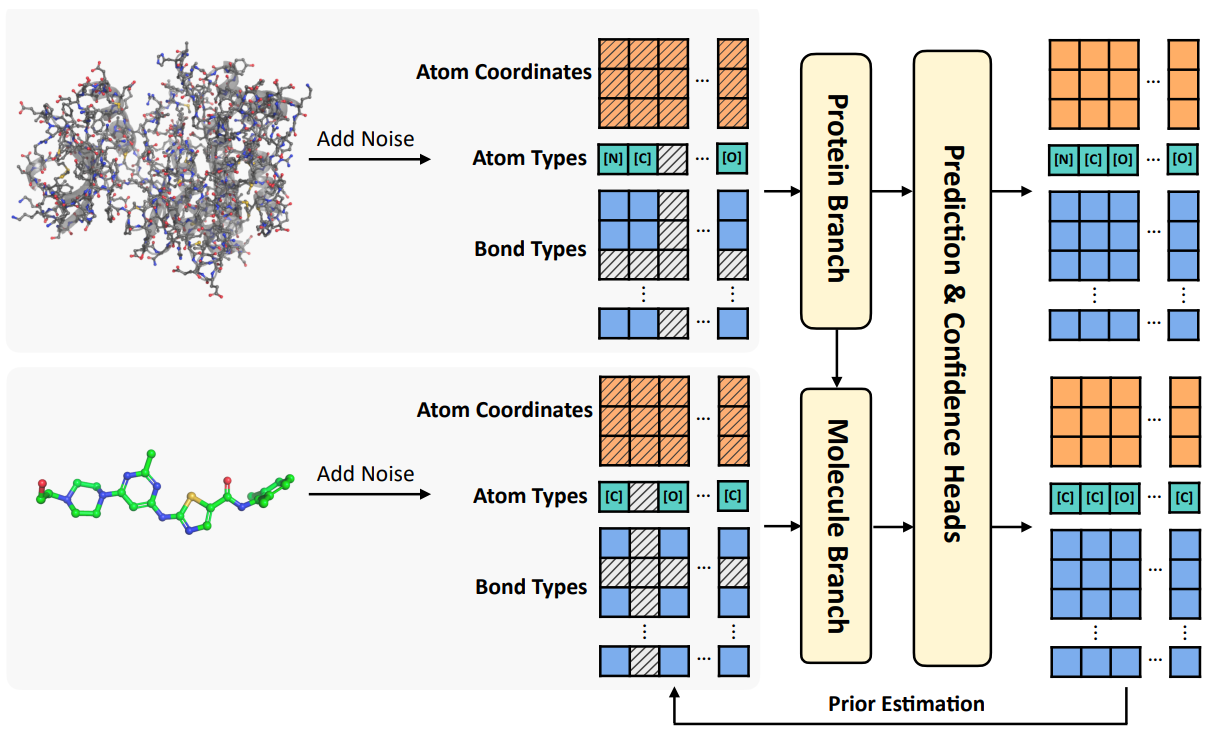
Pharmolix-FM: An All-Atom Multi-Modal Foundation Model for Molecular Modeling and Generation
Yizhen Luo*, Jiashuo Wang*, Siqi Fan*, Zaiqing Nie (* equal contribution)
TechReport 2025
Atomic interactions lie at the heart of molecular structures and functions, serving as the foundation for a wide range of molecular interaction tasks. To establish a unified framework for modeling diverse molecular systems, we propose Pharmolix-FM, a generative model that operates at the all-atom level, enabling consistent representation and interaction modeling across different biomolecules. Pharmolix-FM integrates multiple state-of-the-art generative modeling approaches and allows for unified evaluation across multiple tasks without the need for fine-tuning. Through a systematic comparison of different generative algorithms within this framework, we provide a comprehensive analysis of their effectiveness in molecular interaction tasks. Experimental results demonstrate that Pharmolix-FM achieves superior performance across various tasks, highlighting its potential for advancing molecular interaction modeling.
Pharmolix-FM: An All-Atom Multi-Modal Foundation Model for Molecular Modeling and Generation
Yizhen Luo*, Jiashuo Wang*, Siqi Fan*, Zaiqing Nie (* equal contribution)
TechReport 2025
Atomic interactions lie at the heart of molecular structures and functions, serving as the foundation for a wide range of molecular interaction tasks. To establish a unified framework for modeling diverse molecular systems, we propose Pharmolix-FM, a generative model that operates at the all-atom level, enabling consistent representation and interaction modeling across different biomolecules. Pharmolix-FM integrates multiple state-of-the-art generative modeling approaches and allows for unified evaluation across multiple tasks without the need for fine-tuning. Through a systematic comparison of different generative algorithms within this framework, we provide a comprehensive analysis of their effectiveness in molecular interaction tasks. Experimental results demonstrate that Pharmolix-FM achieves superior performance across various tasks, highlighting its potential for advancing molecular interaction modeling.
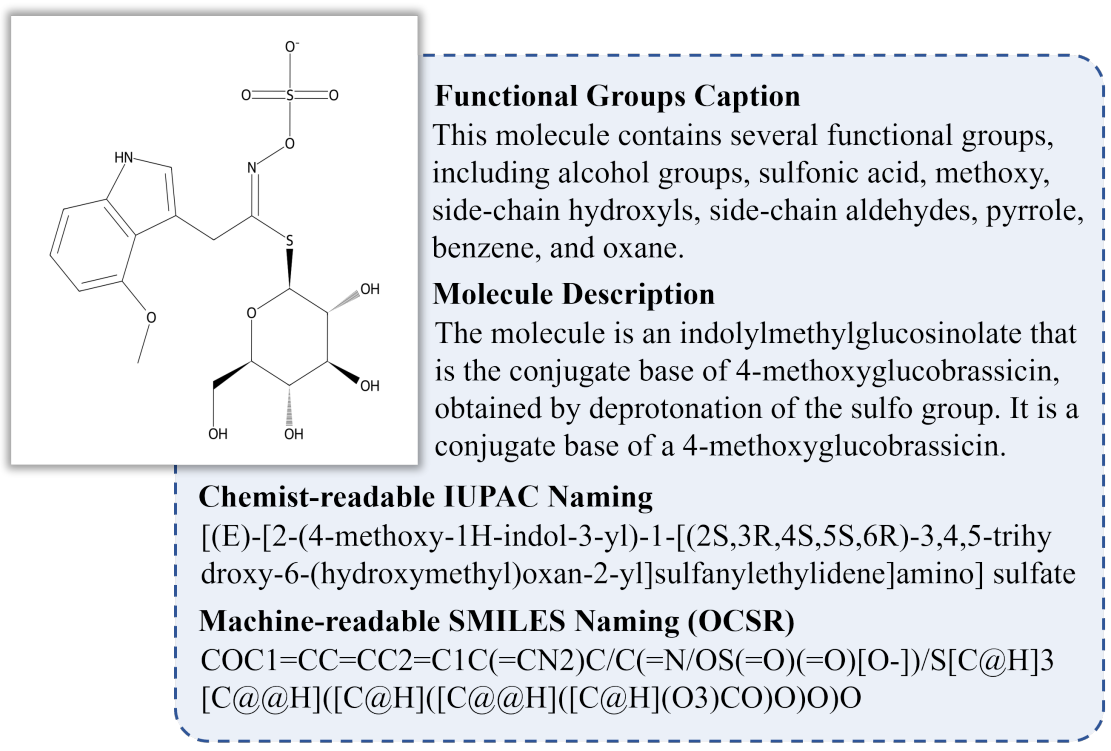
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Siqi Fan, Yuguang Xie, Bowen Cai, Ailin Xie, Gaochao Liu, Mu Qiao, Jie Xing, Zaiqing Nie
TechReport 2025
Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends low-level recognition to multilevel understanding and aims to translate chemical structure diagrams into readable strings for both machine and chemist. To facilitate the development of OCSU technology, we explore both OCSR-based and OCSR-free paradigms. We propose DoubleCheck to enhance OCSR performance via attentive feature enhancement for local ambiguous atoms. It can be cascaded with existing SMILES-based molecule understanding methods to achieve OCSU. Meanwhile, Mol-VL is a vision-language model end-to-end optimized for OCSU. We also construct Vis-CheBI20, the first large-scale OCSU dataset. Through comprehensive experiments, we demonstrate the proposed approaches excel at providing chemist-readable caption for chemical structure diagrams, which provide solid baselines for further research.
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Siqi Fan, Yuguang Xie, Bowen Cai, Ailin Xie, Gaochao Liu, Mu Qiao, Jie Xing, Zaiqing Nie
TechReport 2025
Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends low-level recognition to multilevel understanding and aims to translate chemical structure diagrams into readable strings for both machine and chemist. To facilitate the development of OCSU technology, we explore both OCSR-based and OCSR-free paradigms. We propose DoubleCheck to enhance OCSR performance via attentive feature enhancement for local ambiguous atoms. It can be cascaded with existing SMILES-based molecule understanding methods to achieve OCSU. Meanwhile, Mol-VL is a vision-language model end-to-end optimized for OCSU. We also construct Vis-CheBI20, the first large-scale OCSU dataset. Through comprehensive experiments, we demonstrate the proposed approaches excel at providing chemist-readable caption for chemical structure diagrams, which provide solid baselines for further research.
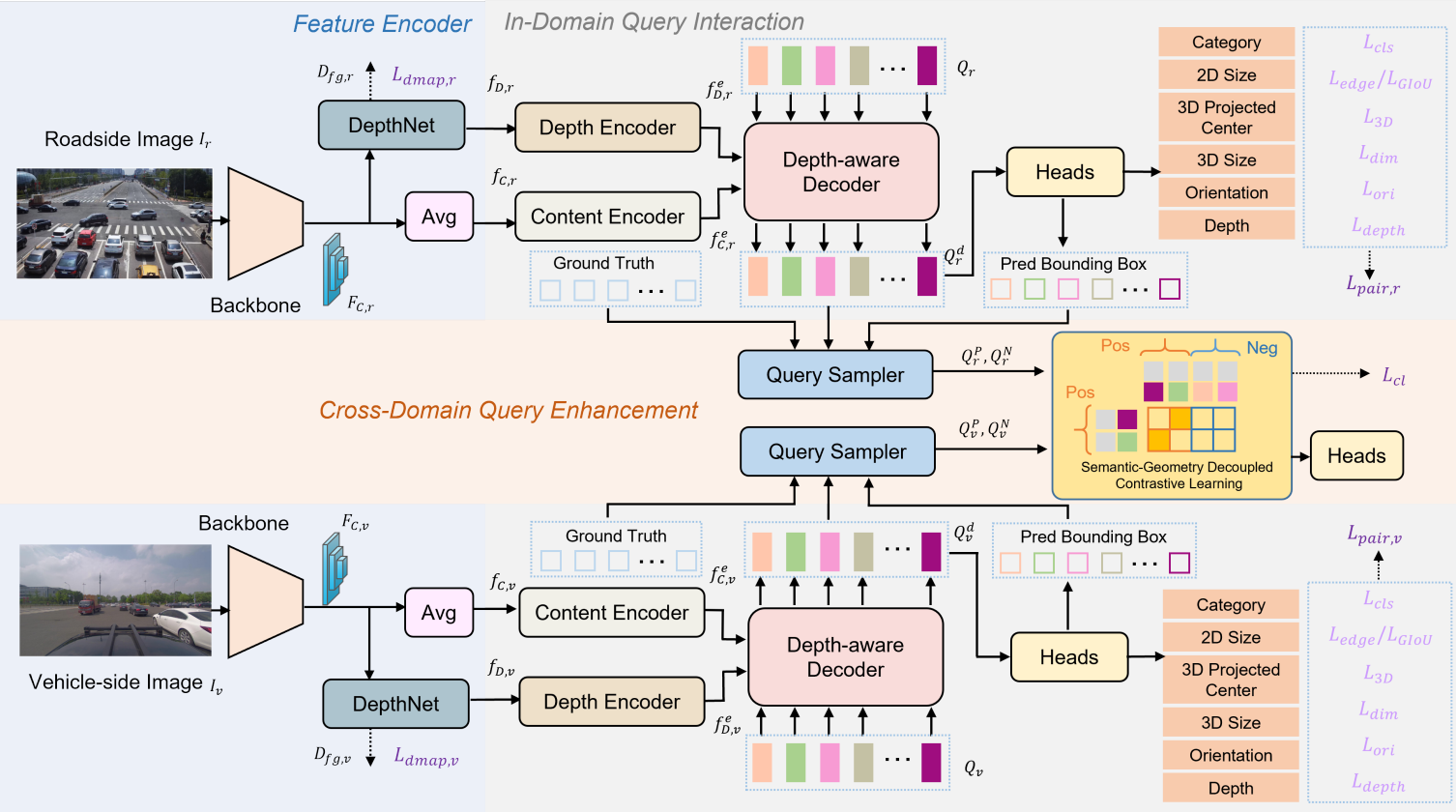
IROAM: Improving Roadside Monocular 3D Object Detection Learning from Autonomous Vehicle Data Domain
Zhe Wang*, Xiaoliang Huo*, Siqi Fan, Jingjing Liu, Ya-Qin Zhang, Yan Wang (* equal contribution)
IEEE International Conference on Robotics and Automation (ICRA) 2025
In autonomous driving, the perception capabilities of the ego-vehicle can be enhanced through roadside sensors, which provide a holistic view of the environment. However, existing monocular detection methods designed for vehicle cameras are not suitable for roadside cameras due to significant viewpoint domain gaps. To bridge this gap and improve roadside monocular 3D object detection, we propose IROAM, a semantic-geometry decoupled contrastive learning framework that simultaneously takes both vehicle-side and roadside data as input. IROAM comprises two key modules. The In-Domain Query Interaction module leverages a transformer to learn content and depth information for each domain and outputs object queries. The Cross-Domain Query Enhancement module, aiming to learn better feature representations from both domains, decouples queries into semantic and geometric parts. Only the semantic part is used for contrastive learning. Experiments demonstrate that IROAM significantly improves the performance of roadside detectors. The results validate IROAM's capability to effectively learn and integrate cross-domain information.
IROAM: Improving Roadside Monocular 3D Object Detection Learning from Autonomous Vehicle Data Domain
Zhe Wang*, Xiaoliang Huo*, Siqi Fan, Jingjing Liu, Ya-Qin Zhang, Yan Wang (* equal contribution)
IEEE International Conference on Robotics and Automation (ICRA) 2025
In autonomous driving, the perception capabilities of the ego-vehicle can be enhanced through roadside sensors, which provide a holistic view of the environment. However, existing monocular detection methods designed for vehicle cameras are not suitable for roadside cameras due to significant viewpoint domain gaps. To bridge this gap and improve roadside monocular 3D object detection, we propose IROAM, a semantic-geometry decoupled contrastive learning framework that simultaneously takes both vehicle-side and roadside data as input. IROAM comprises two key modules. The In-Domain Query Interaction module leverages a transformer to learn content and depth information for each domain and outputs object queries. The Cross-Domain Query Enhancement module, aiming to learn better feature representations from both domains, decouples queries into semantic and geometric parts. Only the semantic part is used for contrastive learning. Experiments demonstrate that IROAM significantly improves the performance of roadside detectors. The results validate IROAM's capability to effectively learn and integrate cross-domain information.
2024
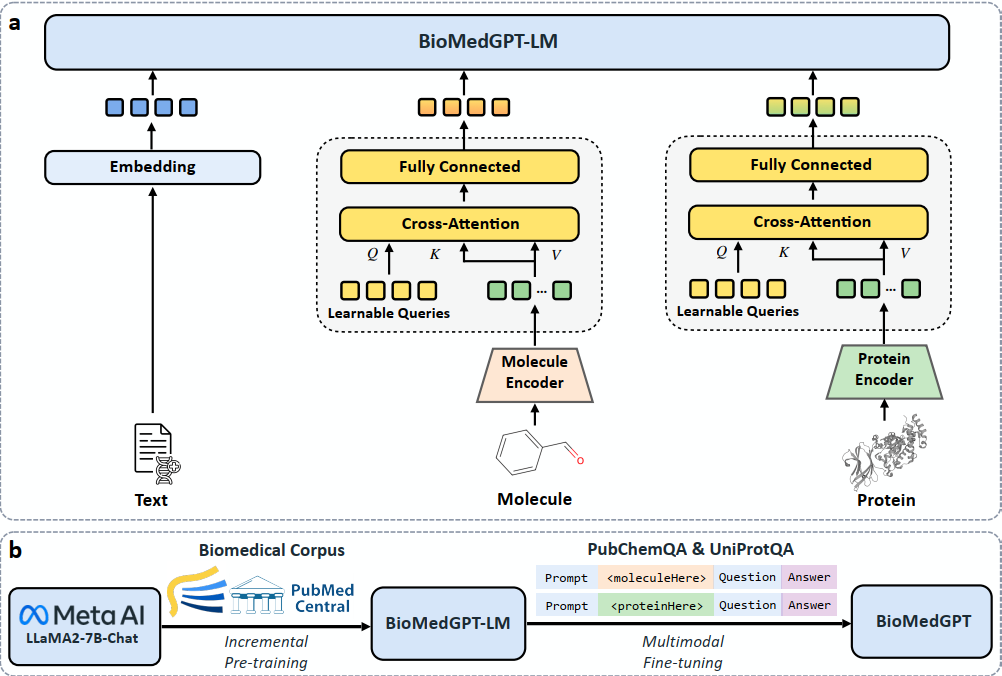
BioMedGPT: An Open Multimodal Large Language Model for BioMedicine
Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Massimo Hong, Yushuai Wu, Mu Qiao, Zaiqing Nie
IEEE Journal of Biomedical and Health Informatics (J-BHI) 2024
Recent advances in large language models (LLMs) like ChatGPT have shed light on the development of knowledgeable and versatile AI research assistants in various scientific domains. However, they fall short in biomedical applications due to a lack of proprietary biomedical knowledge and deficiencies in handling biological sequences for molecules and proteins. To address these issues, we present BioMedGPT, a multimodal large language model for assisting biomedical research. We first incorporate domain expertise into LLMs by incremental pre-training on large-scale biomedical literature. Then, we harmonize 2D molecular graphs, protein sequences, and natural language within a unified, parameter-efficient fusion architecture by fine-tuning on multimodal question-answering datasets. Through comprehensive experiments, we show that BioMedGPT performs on par with human experts in comprehending biomedical documents and answering research questions. It also exhibits promising capability in analyzing intricate functions and properties of novel molecules and proteins, surpassing state-of-the-art LLMs by 17.1% and 49.8% absolute gains respectively in ROUGE-L on molecule and protein question-answering.
BioMedGPT: An Open Multimodal Large Language Model for BioMedicine
Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Massimo Hong, Yushuai Wu, Mu Qiao, Zaiqing Nie
IEEE Journal of Biomedical and Health Informatics (J-BHI) 2024
Recent advances in large language models (LLMs) like ChatGPT have shed light on the development of knowledgeable and versatile AI research assistants in various scientific domains. However, they fall short in biomedical applications due to a lack of proprietary biomedical knowledge and deficiencies in handling biological sequences for molecules and proteins. To address these issues, we present BioMedGPT, a multimodal large language model for assisting biomedical research. We first incorporate domain expertise into LLMs by incremental pre-training on large-scale biomedical literature. Then, we harmonize 2D molecular graphs, protein sequences, and natural language within a unified, parameter-efficient fusion architecture by fine-tuning on multimodal question-answering datasets. Through comprehensive experiments, we show that BioMedGPT performs on par with human experts in comprehending biomedical documents and answering research questions. It also exhibits promising capability in analyzing intricate functions and properties of novel molecules and proteins, surpassing state-of-the-art LLMs by 17.1% and 49.8% absolute gains respectively in ROUGE-L on molecule and protein question-answering.
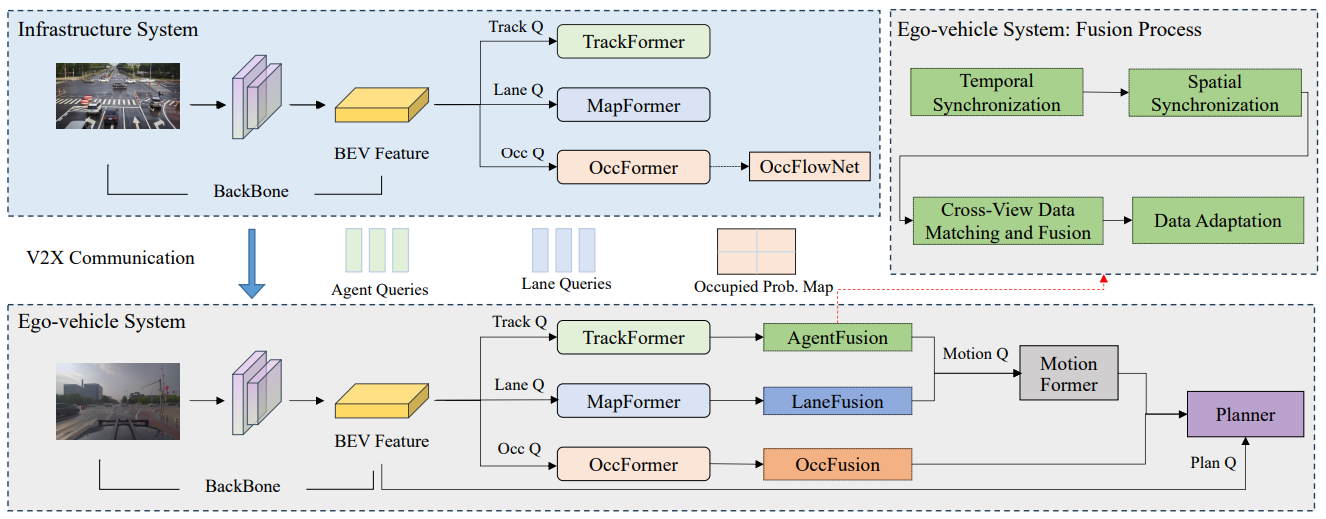
End-to-End Autonomous Driving through V2X Cooperation
Haibao Yu, Wenxian Yang, Jiaru Zhong, Zhenwei Yang, Siqi Fan, Ping Luo, Zaiqing Nie
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) 2024
Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance.
End-to-End Autonomous Driving through V2X Cooperation
Haibao Yu, Wenxian Yang, Jiaru Zhong, Zhenwei Yang, Siqi Fan, Ping Luo, Zaiqing Nie
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) 2024
Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance.

RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Ruiyang Hao*, Siqi Fan*, Yingru Dai, Zhenlin Zhang, Chenxi Li, Yuntian Wang, Haibao Yu, Wenxian Yang, Jirui Yuan, Zaiqing Nie (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Orienting a comprehensive understanding of a traffic area, we need Roadside Cooperative Perception (RCooper) to achieve area-coverage roadside perception. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Ruiyang Hao*, Siqi Fan*, Yingru Dai, Zhenlin Zhang, Chenxi Li, Yuntian Wang, Haibao Yu, Wenxian Yang, Jirui Yuan, Zaiqing Nie (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Orienting a comprehensive understanding of a traffic area, we need Roadside Cooperative Perception (RCooper) to achieve area-coverage roadside perception. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research.
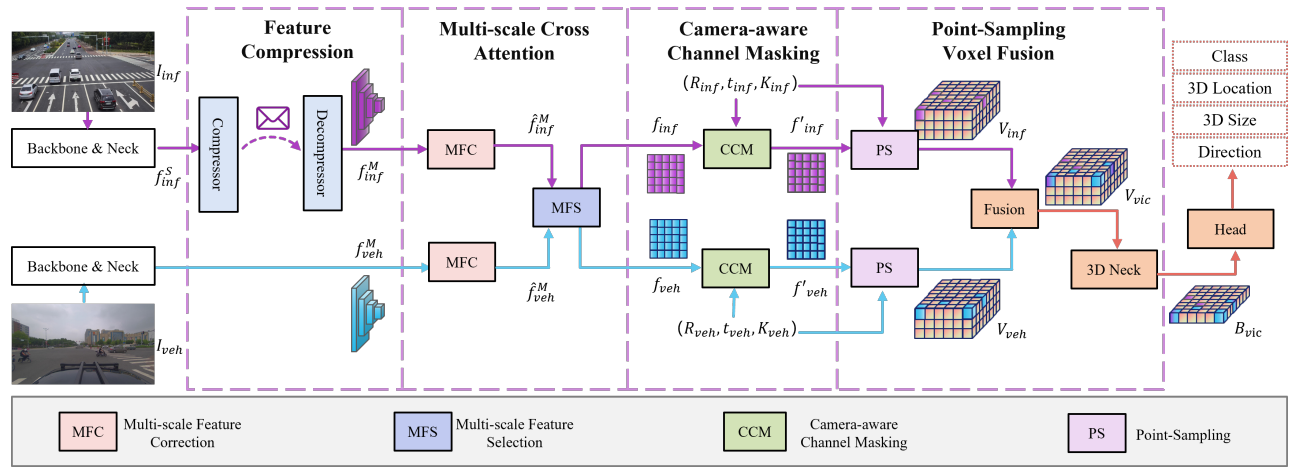
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Zhe Wang, Siqi Fan, Xiaoliang Huo, Tongda Xu, Yan Wang, Jingjing Liu, Yilun Chen, Ya-Qin Zhang
IEEE International Conference on Robotics and Automation (ICRA) 2024
In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: 1) inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Zhe Wang, Siqi Fan, Xiaoliang Huo, Tongda Xu, Yan Wang, Jingjing Liu, Yilun Chen, Ya-Qin Zhang
IEEE International Conference on Robotics and Automation (ICRA) 2024
In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: 1) inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
2023
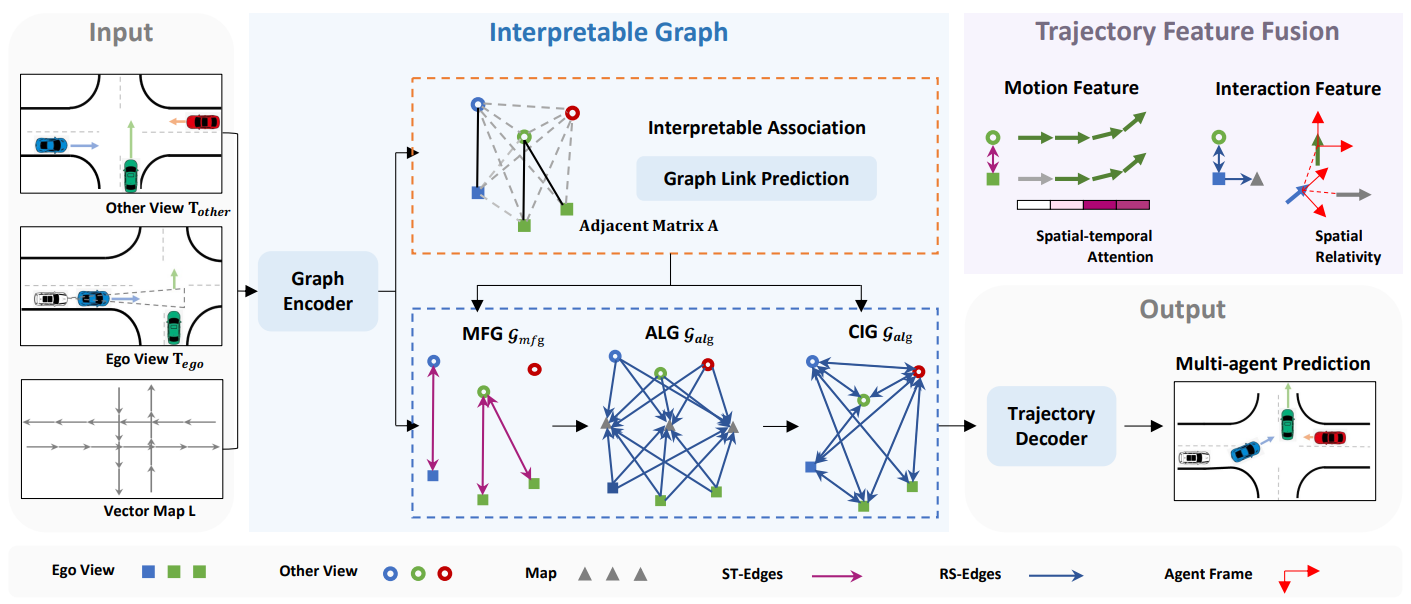
Learning Cooperative Trajectory Representations for Motion Forecasting
Hongzhi Ruan@, Haibao Yu, Wenxian Yang, Siqi Fan, Zaiqing Nie (@ mentored)
Advances in Neural Information Processing Systems (NeurIPS) 2024
Motion forecasting is an essential task for autonomous driving, and utilizing information from infrastructure and other vehicles can enhance forecasting capabilities. Existing research mainly focuses on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction context of traffic participants observed from cooperative devices. In this paper, we propose a forecasting-oriented representation paradigm to utilize motion and interaction features from cooperative information. Specifically, we present V2X-Graph, a representative framework to achieve interpretable and end-to-end trajectory feature fusion for cooperative motion forecasting. V2X-Graph is evaluated on V2X-Seq in vehicle-to-infrastructure (V2I) scenarios. To further evaluate on vehicle-to-everything (V2X) scenario, we construct the first real-world V2X motion forecasting dataset V2X-Traj, which contains multiple autonomous vehicles and infrastructure in every scenario. Experimental results on both V2X-Seq and V2X-Traj show the advantage of our method. We hope both V2X-Graph and V2X-Traj will benefit the further development of cooperative motion forecasting.
Learning Cooperative Trajectory Representations for Motion Forecasting
Hongzhi Ruan@, Haibao Yu, Wenxian Yang, Siqi Fan, Zaiqing Nie (@ mentored)
Advances in Neural Information Processing Systems (NeurIPS) 2024
Motion forecasting is an essential task for autonomous driving, and utilizing information from infrastructure and other vehicles can enhance forecasting capabilities. Existing research mainly focuses on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction context of traffic participants observed from cooperative devices. In this paper, we propose a forecasting-oriented representation paradigm to utilize motion and interaction features from cooperative information. Specifically, we present V2X-Graph, a representative framework to achieve interpretable and end-to-end trajectory feature fusion for cooperative motion forecasting. V2X-Graph is evaluated on V2X-Seq in vehicle-to-infrastructure (V2I) scenarios. To further evaluate on vehicle-to-everything (V2X) scenario, we construct the first real-world V2X motion forecasting dataset V2X-Traj, which contains multiple autonomous vehicles and infrastructure in every scenario. Experimental results on both V2X-Seq and V2X-Traj show the advantage of our method. We hope both V2X-Graph and V2X-Traj will benefit the further development of cooperative motion forecasting.
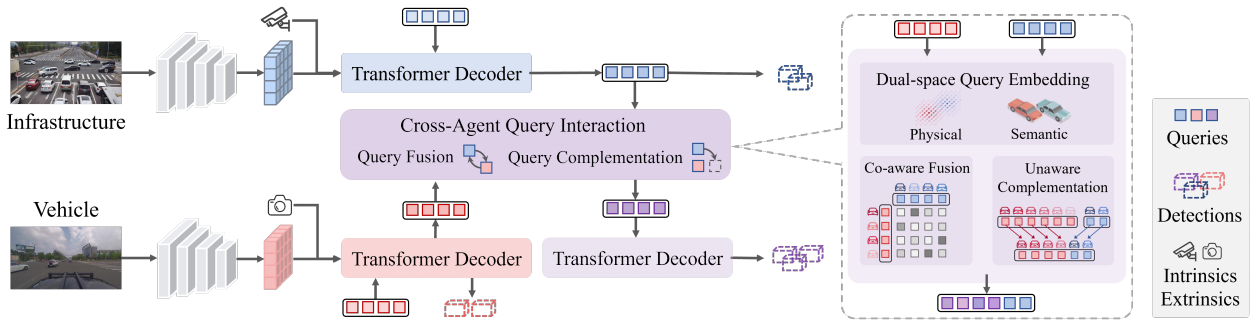
QUEST: Query Stream for Practical Cooperative Perception
Siqi Fan, Haibao Yu, Wenxian Yang, Jirui Yuan, Zaiqing Nie
IEEE International Conference on Robotics and Automation (ICRA) 2024
Aiming at interpretable and flexible cooperative perception, we propose the concept of query cooperation in this paper, which enables instance-level feature interaction among agents via the query stream. To specifically describe the query cooperation, a representative cooperative perception framework (QUEST) is proposed. It performs cross-agent query interaction by fusion and complementation, which are designed for co-aware objects and unaware objects respectively. Taking camera-based vehicle-infrastructure cooperative perception as a typical scenario, we generate the camera-centric cooperation labels of DAIR-V2X-Seq and evaluate the proposed framework on it. The experimental results not only demonstrate the effectiveness but also show the advantages of transmission flexibility and robustness to packet dropout. In addition, we discuss the pros and cons of query cooperation paradigm from the possible extensions and foreseeable limitations.
QUEST: Query Stream for Practical Cooperative Perception
Siqi Fan, Haibao Yu, Wenxian Yang, Jirui Yuan, Zaiqing Nie
IEEE International Conference on Robotics and Automation (ICRA) 2024
Aiming at interpretable and flexible cooperative perception, we propose the concept of query cooperation in this paper, which enables instance-level feature interaction among agents via the query stream. To specifically describe the query cooperation, a representative cooperative perception framework (QUEST) is proposed. It performs cross-agent query interaction by fusion and complementation, which are designed for co-aware objects and unaware objects respectively. Taking camera-based vehicle-infrastructure cooperative perception as a typical scenario, we generate the camera-centric cooperation labels of DAIR-V2X-Seq and evaluate the proposed framework on it. The experimental results not only demonstrate the effectiveness but also show the advantages of transmission flexibility and robustness to packet dropout. In addition, we discuss the pros and cons of query cooperation paradigm from the possible extensions and foreseeable limitations.
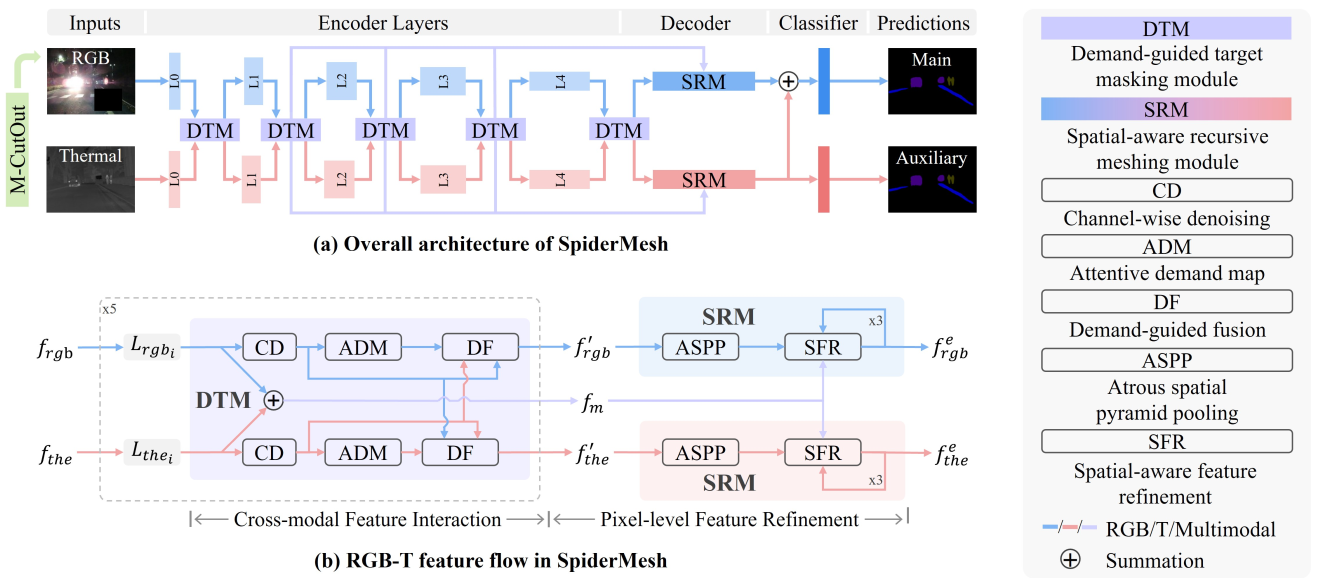
SpiderMesh: Spatial-aware Demand-guided Recursive Meshing for RGB-T Semantic Segmentation
Siqi Fan, Zhe Wang, Yan Wang, Jingjing Liu
[TechReport'2023] SOTA on RGB-T segmentation benchmarks 2023
We proposed a systematic multimodal learning approach for practical RGB-T (thermal) segmentation, termed Spatial-aware Demand-guided Recursive Meshing (SpiderMesh), to leverage the additional thermal signals in a proactive manner. SpiderMesh (1) proactively compensates inadequate contextual semantics in optically-impaired regions via a demand-guided target masking algorithm and (2) refines multimodal semantic features with recursive meshing to improve pixel-level semantic analysis performance. We further introduce an asymmetric data augmentation technique M-CutOut, and enable semi-supervised learning to fully utilize RGB-T labels only sparsely available in practical use. It is evaluated on MFNet and PST900 datasets, and achieves SOTA performance on standard RGB-T segmentation benchmarks.
SpiderMesh: Spatial-aware Demand-guided Recursive Meshing for RGB-T Semantic Segmentation
Siqi Fan, Zhe Wang, Yan Wang, Jingjing Liu
[TechReport'2023] SOTA on RGB-T segmentation benchmarks 2023
We proposed a systematic multimodal learning approach for practical RGB-T (thermal) segmentation, termed Spatial-aware Demand-guided Recursive Meshing (SpiderMesh), to leverage the additional thermal signals in a proactive manner. SpiderMesh (1) proactively compensates inadequate contextual semantics in optically-impaired regions via a demand-guided target masking algorithm and (2) refines multimodal semantic features with recursive meshing to improve pixel-level semantic analysis performance. We further introduce an asymmetric data augmentation technique M-CutOut, and enable semi-supervised learning to fully utilize RGB-T labels only sparsely available in practical use. It is evaluated on MFNet and PST900 datasets, and achieves SOTA performance on standard RGB-T segmentation benchmarks.
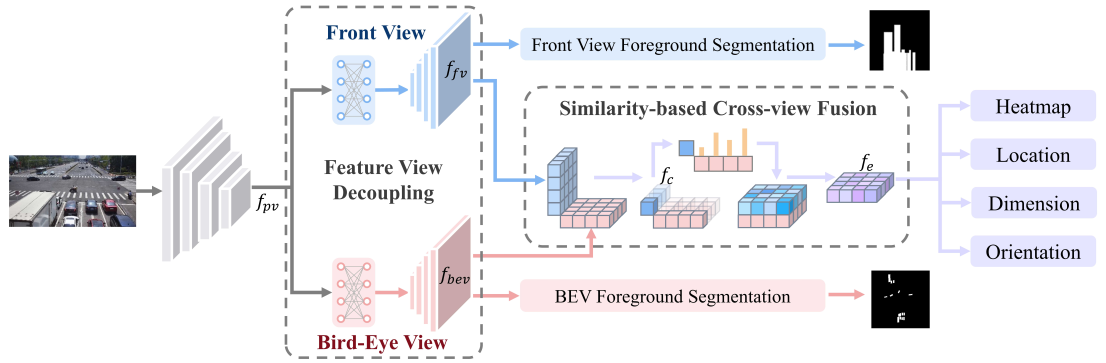
Calibration-free BEV Representation for Infrastructure Perception
Siqi Fan, Zhe Wang, Xiaoliang Huo, Yan Wang, Jingjing Liu
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2023
Addressing the practical challenges of various installation postures and calibration noises caused by inevitable natural factors (e.g., wind and snow), we point out the significant performance degradation of calibration-based BEV detection approach under calibration noise, and propose the Calibration-free BEV Representation network (CBR) for infrastructure perception. CBR achieves feature view standardization via decoupled feature reconstruction. The perspective view features are decoupled to front view and bird-eye view via MLPs without any calibration parameters, and orthogonal feature fusion is similarity-based without additional depth supervision. It is evaluated on the large-scale real-world dataset DAIR-V2X, and achieves a better accuracy-robustness balance.
[Paper] [Code] [Graphic Abstract] [Poster] [PPT] [Video] [第三方中文解读]
Calibration-free BEV Representation for Infrastructure Perception
Siqi Fan, Zhe Wang, Xiaoliang Huo, Yan Wang, Jingjing Liu
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2023
Addressing the practical challenges of various installation postures and calibration noises caused by inevitable natural factors (e.g., wind and snow), we point out the significant performance degradation of calibration-based BEV detection approach under calibration noise, and propose the Calibration-free BEV Representation network (CBR) for infrastructure perception. CBR achieves feature view standardization via decoupled feature reconstruction. The perspective view features are decoupled to front view and bird-eye view via MLPs without any calibration parameters, and orthogonal feature fusion is similarity-based without additional depth supervision. It is evaluated on the large-scale real-world dataset DAIR-V2X, and achieves a better accuracy-robustness balance.
[Paper] [Code] [Graphic Abstract] [Poster] [PPT] [Video] [第三方中文解读]
2022
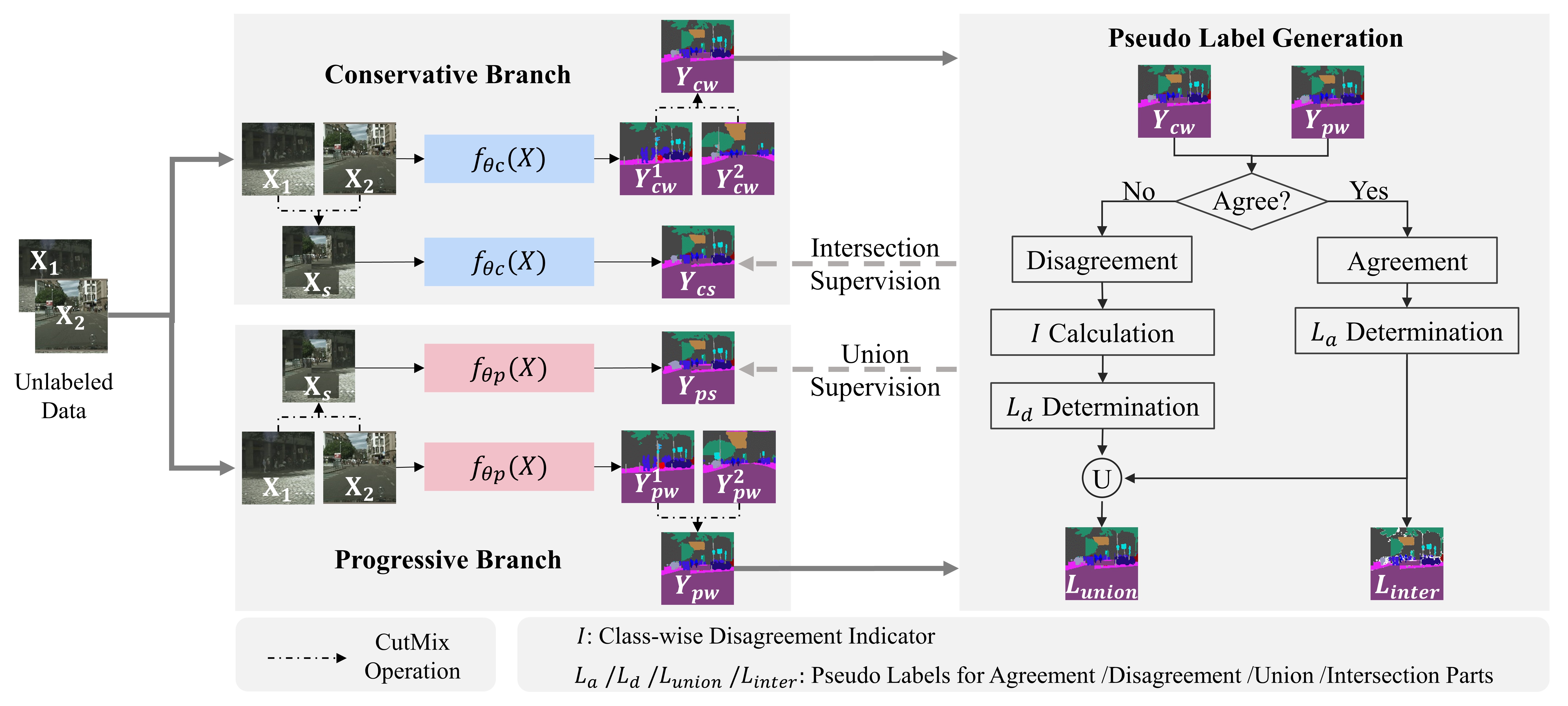
Conservative-Progressive Collaborative Learning for Semi-supervised Semantic Segmentation
Siqi Fan, Fenghua Zhu, Zunlei Feng, Yisheng Lv, Mingli Song, Fei-Yue Wang
IEEE Transactions on Image Processing (T-IP) 2022
We proposed a novel semi-supervised learning approach for semantic segmentation, termed Conservative-Progressive Collaborative Learning (CPCL), to not only take the advantage of the high-quality labels but also make the full use of the large quantity of the unlabeled data. CPCL is realized via the intersection and union pseudo supervision, which cooperate with each other and achieve the collaboration of conservative evolution and progressive exploration. In addition, a confidence-based dynamic loss is proposed to reduce the pseudo supervision noise. CPCL is simple, efficient and flexible. It is evaluated on Cityscapes and PASCAL VOC 2012, and achieves SOTA performance for semi-supervised semantic segmentation, especially in low-data regime.
Conservative-Progressive Collaborative Learning for Semi-supervised Semantic Segmentation
Siqi Fan, Fenghua Zhu, Zunlei Feng, Yisheng Lv, Mingli Song, Fei-Yue Wang
IEEE Transactions on Image Processing (T-IP) 2022
We proposed a novel semi-supervised learning approach for semantic segmentation, termed Conservative-Progressive Collaborative Learning (CPCL), to not only take the advantage of the high-quality labels but also make the full use of the large quantity of the unlabeled data. CPCL is realized via the intersection and union pseudo supervision, which cooperate with each other and achieve the collaboration of conservative evolution and progressive exploration. In addition, a confidence-based dynamic loss is proposed to reduce the pseudo supervision noise. CPCL is simple, efficient and flexible. It is evaluated on Cityscapes and PASCAL VOC 2012, and achieves SOTA performance for semi-supervised semantic segmentation, especially in low-data regime.
2021
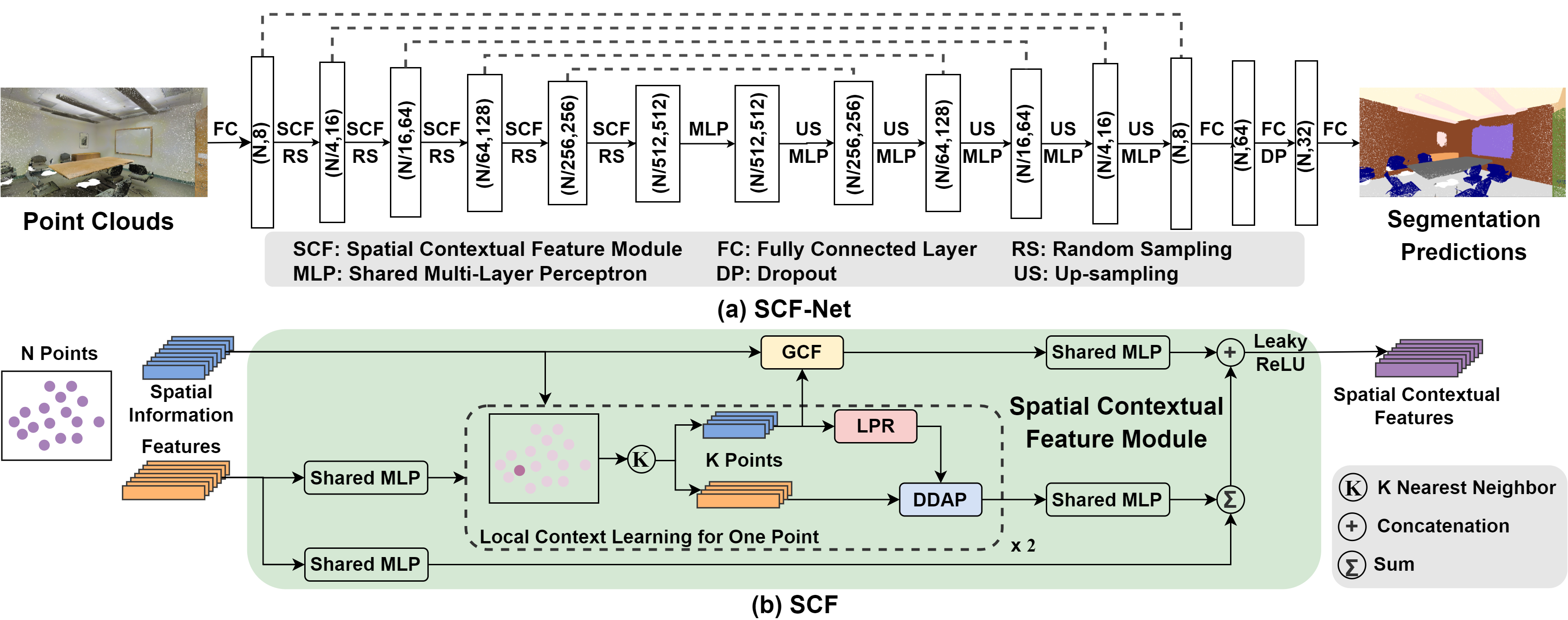
SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation
Siqi Fan, Qiulei Dong, Fenghua Zhu, Yisheng Lv, Peijun Ye, Fei-Yue Wang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021
We proposed a systematic approach for learning the spatial contextual feature, including the local spatial contextual information representation, the local spatial contextual feature learning, and the global spatial contextual feature learning. On the basis of that, a corresponding module for spatial contextual learning is designed. The module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called SCF-Net. It is evaluated on S3DIS and Semantic3D, and performs better than several SOTA methods in most cases.
SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation
Siqi Fan, Qiulei Dong, Fenghua Zhu, Yisheng Lv, Peijun Ye, Fei-Yue Wang
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021
We proposed a systematic approach for learning the spatial contextual feature, including the local spatial contextual information representation, the local spatial contextual feature learning, and the global spatial contextual feature learning. On the basis of that, a corresponding module for spatial contextual learning is designed. The module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called SCF-Net. It is evaluated on S3DIS and Semantic3D, and performs better than several SOTA methods in most cases.
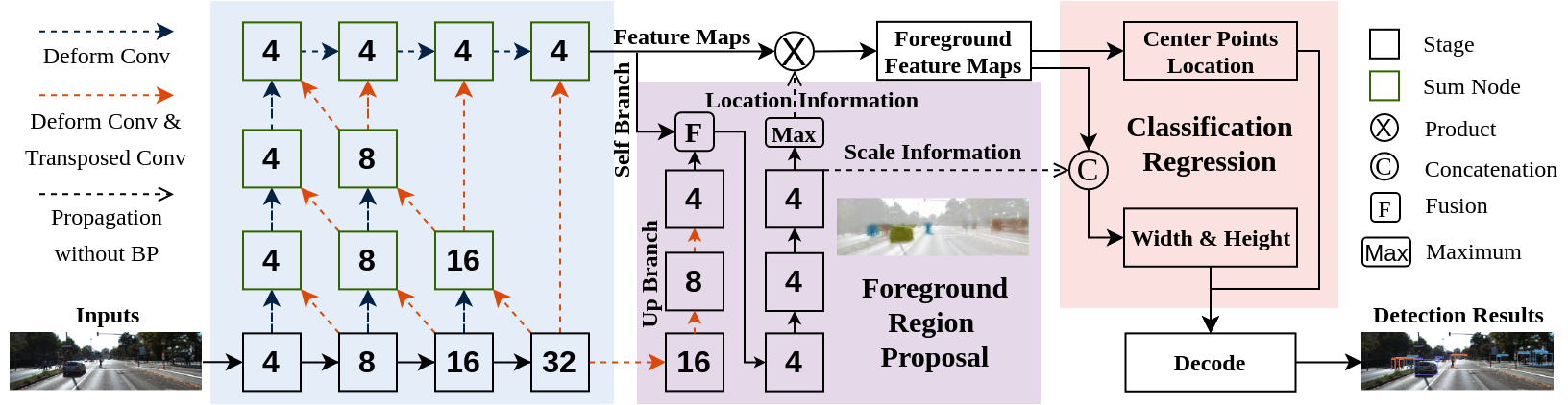
FII-CenterNet: An Anchor-Free Detector With Foreground Attention for Traffic Object Detection
Siqi Fan, Fenghua Zhu, Shichao Chen, Hui Zhang, Bin Tian, Yisheng Lv, Fei-Yue Wang
IEEE Transactions on Vehicular Technology (T-VT) 2021
We proposed a foreground segmentation approach for anchor-free object detection, which could alleviate the background influences under the complex traffic environment with little extra computation cost. On the basis of that, a novel traffic object detection network with foreground attention, called FII-CenterNet, is developed. It is evaluated on KITTI and PASCAL VOC, and achieves the SOTA performance in both accuracy and efficiency.
FII-CenterNet: An Anchor-Free Detector With Foreground Attention for Traffic Object Detection
Siqi Fan, Fenghua Zhu, Shichao Chen, Hui Zhang, Bin Tian, Yisheng Lv, Fei-Yue Wang
IEEE Transactions on Vehicular Technology (T-VT) 2021
We proposed a foreground segmentation approach for anchor-free object detection, which could alleviate the background influences under the complex traffic environment with little extra computation cost. On the basis of that, a novel traffic object detection network with foreground attention, called FII-CenterNet, is developed. It is evaluated on KITTI and PASCAL VOC, and achieves the SOTA performance in both accuracy and efficiency.
2020
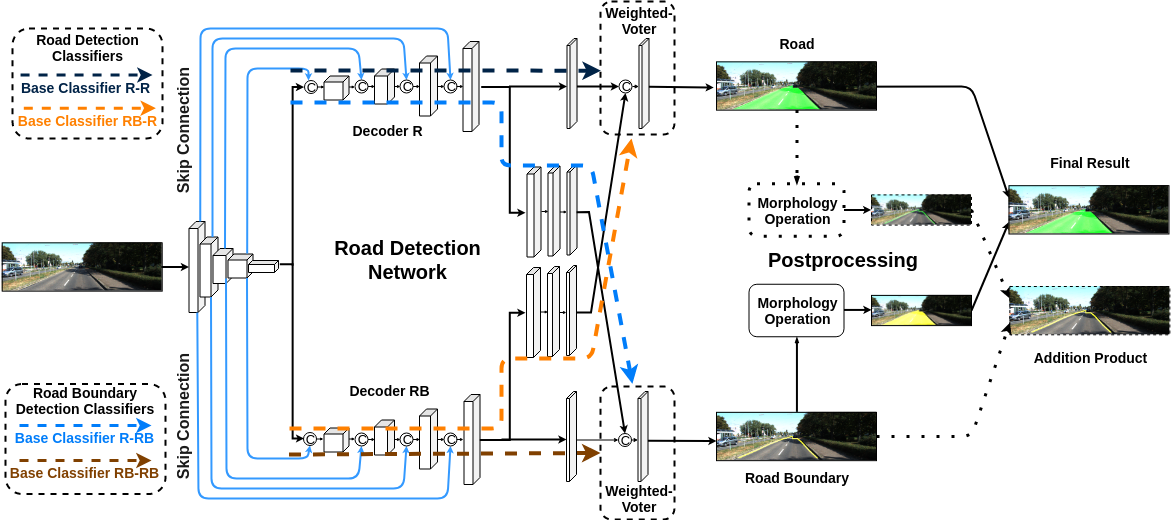
Improving Road Detection Results Based on Ensemble Learning and Key Samples Focusing
Siqi Fan, Fenghua Zhu, Hui Zhang, Yisheng Lv, Xiao Wang, Gang Xiong, Fei-Yue Wang
IEEE International Conference on Intelligent Transportation Systems (ITSC) 2020
We proposed a road detection network, which integrates the classification results based on different feature combinations by weighted voting. To focus on key samples, a novel loss function is proposed. The loss function can attach importance to hard samples and pay different attention to missed detection and false detection. The method is evaluated on KITTI, and its effectiveness is verified.
Improving Road Detection Results Based on Ensemble Learning and Key Samples Focusing
Siqi Fan, Fenghua Zhu, Hui Zhang, Yisheng Lv, Xiao Wang, Gang Xiong, Fei-Yue Wang
IEEE International Conference on Intelligent Transportation Systems (ITSC) 2020
We proposed a road detection network, which integrates the classification results based on different feature combinations by weighted voting. To focus on key samples, a novel loss function is proposed. The loss function can attach importance to hard samples and pay different attention to missed detection and false detection. The method is evaluated on KITTI, and its effectiveness is verified.